The Clean Architecture in Python
In this article we’ll show case the Clean Architecture (or at least, my interpretation of it). Simply put, the Clean Architecture is a way to structure code at the application level (it’s more global than just a design pattern for example). Ultimately, the goal is to improve the separation of concerns between the components of a software and reduce coupling. In his original blog post, Robert C. Martin (aka Uncle Bob) says the Clean architecture produces systems that are:
- Independent of Frameworks. The architecture does not depend on the existence of some library of feature laden software. This allows you to use such frameworks as tools, rather than having to cram your system into their limited constraints.
- Testable. The business rules can be tested without the UI, Database, Web Server, or any other external element.
- Independent of UI. The UI can change easily, without changing the rest of the system. A Web UI could be replaced with a console UI, for example, without changing the business rules.
- Independent of Database. You can swap out Oracle or SQL Server, for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.
- Independent of any external agency. In fact your business rules simply don’t know anything at all about the outside world.
The diagram below is a visual representation of the concept:
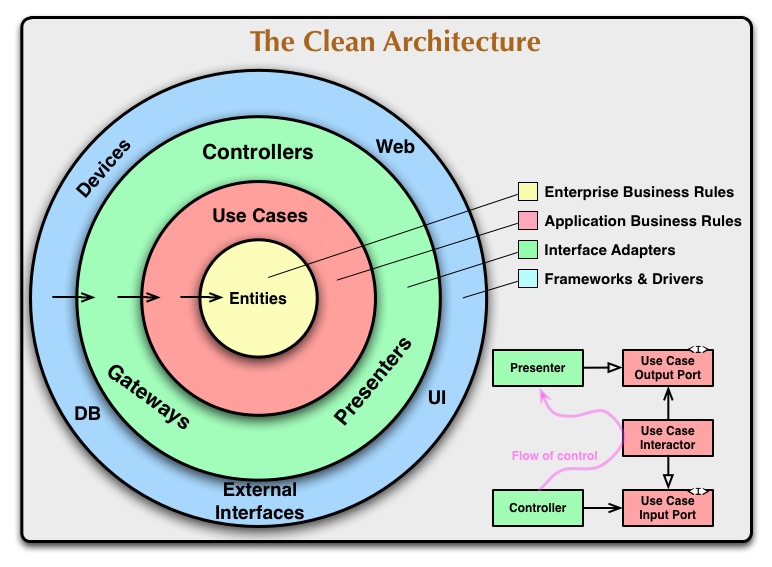
The final state of the code is available here.
How does it work?
The separation of concerns is achieved by splitting the software into layers, and by normalizing the communication between the layers. Let’s have a look at these layers.
Entities
This layer of the clean architecture contains a representation of the
domain models, that is everything your project needs to interact with
and is sufficiently complex to require a specific representation. They
encapsulate Enterprise wide business rules. Generally they take the form of
data structures that contain state that other components in your system
use to do something. For example if you’re building an inventory system,
you should model the physical objects that you want to inventory as entities,
e.g: the Car entity, the Book entity, etc.
It is very important to understand that the entities in this layer are different from the usual models from ORMs like SQLAlchemy. The entities are not connected with a storage system, so they cannot be directly saved or queried using methods of their classes. In fact, they shouldn’t even know about the existence of a persistence layer.
Use Cases (a.k.a Interactors)
This layer contains the use cases implemented by the system. Use cases are the processes that happen in your application, where you use your domain models (aka entities) to perform an action. These use cases orchestrate the flow of data to and from the entities, and direct those entities to use their enterprise wide business rules to achieve the goals of the use case.
A use case should be as small a possible. It is very important to isolate small actions in use cases, as this makes the whole system easier to test, understand and maintain. Several use cases can be combined.
If we use the inventory example again, here are some examples of use cases:
- add a new item to the inventory
- remove an item from the inventory
Burn the inventory- relabel an item
Gateways
This layer is the membrane between the internal layers and the external layers. It converts data coming from the web or the database into entities, and then passes these entities to the use cases. This also works in the opposite direction: this layer will convert entities sent by the use cases into a form that can be persisted by the database or sent through the web.
The original blog post clearly states:
No code inward of this circle should know anything at all about the database. If the database is a SQL database, then all the SQL should be restricted to this layer.
Following this statement, the data registry that we’ll see later would belong to this layer.
External systems
This layer contains stuff like like the database or the web framework. Most of the time you will have little control over this layer and you will just use it. It’s also hard to conceptualize where this layer starts, but I personally represent it like this:
- when you’re calling a database library/driver to write something to the database, you’re entering this layer
- when you’re serializing a response to JSON at the very end of a web framework (e.g Flask, FastAPI) endpoint, you’re entering this layer
From the original blog post:
This layer is where all the details go. The Web is a detail. The database is a detail. We keep these things on the outside where they can do little harm.
The dependency rule
The original blog post talks about one rule that holds all the layers together:
The dependency rule says that source code dependencies can only point inwards. Nothing in an inner circle can know anything at all about something in an outer circle. In particular, the name of something declared in an outer circle must not be mentioned by the code in an inner circle. That includes, functions, classes, variables, or any other named software entity.
In practice, I prefer this rule (from this book), because it’s simpler to conceptualize:
Talk inwards with simple structures, talk outwards through interfaces

A practical example
To make all this theory tangible, we will look at a realistic and useful example…Collecting and storing spells from Harry Potter!

We’ll use the freely accessible WizardWorldAPI. The swagger page (a page documenting the API) is accessible here.
Building the Spell entity
Let’s look at the GET /Spells endpoint:
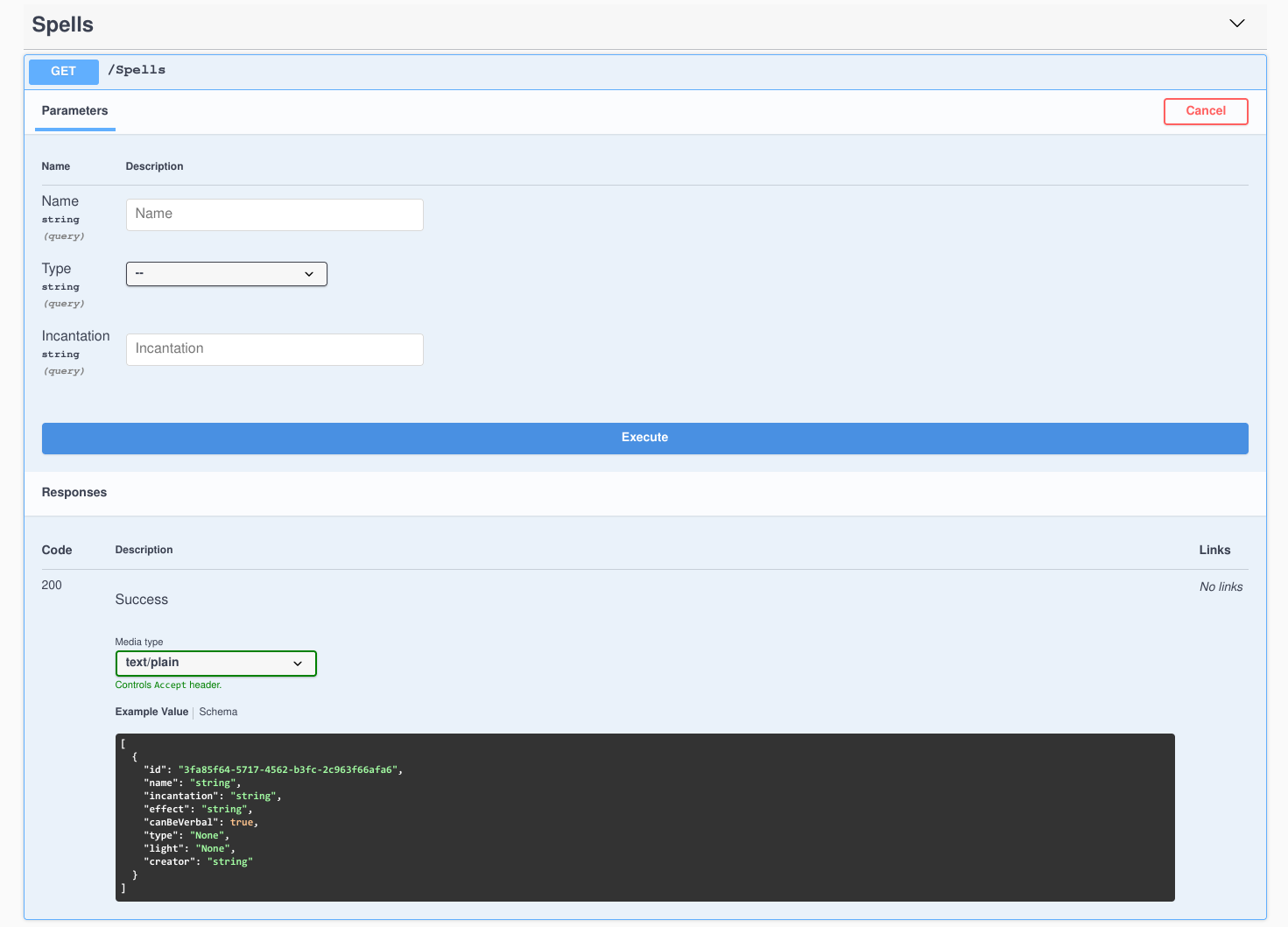
This endpoint accepts the Name, Type and Incantation parameters
for filtering the spells that will be returned, but they’re all optional.
If we look at the Response section, we can learn more about the data we’ll
get back once we query the API:
[
{
"id": "3fa85f64-5717-4562-b3fc-2c963f66afa6",
"name": "string",
"incantation": "string",
"effect": "string",
"canBeVerbal": true,
"type": "None",
"light": "None",
"creator": "string"
}
]
From this hint we can write the class for our first entity. In a file
entities.py, let’s insert:
from typing import NamedTuple
class Spell(NamedTuple):
id: str
name: str
incantation: str | None
effect: str
canBeVerbal: bool | None
type: str
light: str
creator: str | None
To model a spell and all its data, I chose to use a NamedTuple. This is a
debatable choice with pros and cons, but I like it because it’s immutable,
simple, and it’s part of the standard library. A dataclass is also a valid
choice when it comes to the standard library, especially if you need to mutate
the entity after its creation, for some reason (even though I’d recommend
avoiding this situation). Using pydantic
to model entities is another good option - especially because it provides
input validation - but it isn’t part of the standard library. What you really
shouldn’t do is define your own, plain class for Spell because you won’t
be able to benefit from the features that all the types I just mentioned
implement out of the box: serialization, concise syntax, potential input
validation, immutability, etc.
To instantiate a Spell, we could do something like this:
data = {
"id": "fbd3cb46-c174-4843-a07e-fd83545dce58",
"name": "Opening Charm",
"incantation": "Aberto",
"effect": "Opens doors",
"canBeVerbal": True,
"type": "Charm",
"light": "Blue",
"creator": None,
}
spell = Spell(**data)
But generally I prefer implementing uniform interfaces to serialize and deserialize my entities directly on the entity classes. Something like that:
from __future__ import annotations # Necessary to type hint return type from_dict
from typing import NamedTuple
class Spell(NamedTuple):
id: str
name: str
incantation: str | None
effect: str
canBeVerbal: bool | None
type: str
light: str
creator: str | None
@classmethod
def from_dict(cls, data: dict) -> Spell:
return cls(**data)
def to_dict(self) -> dict:
return self._asdict()
I like using from_* class methods to signal how a Spell entity can be
created. Here I just created the from_dict method to create a Spell
from a dict, but we could imagine having a from_database_payload method to
create a Spell from data coming from a database, where we would implement
some extra logic. I like this pattern because I think an entity definition
should convey what is the best way to instantiate the entity.
I also like implementing a to_dict method on my entities. You’ll
notice that here this method doesn’t do much, and I could just use
spell._asdict(). But in complex projects you’ll definitely end up using
different types to implement your entities, probably a mix of NamedTuple,
dataclasses and pydantic. These types all implement the serialization
to dict differently, e.g asdict(data_class_here) for dataclasses
(doc).
Having a uniform to_dict method abstracts away the implementation details
of your entities.
Building the client to fetch the spells
The client is part of the Gateways layer and it’ll interact with an external system (the spells API). Note that the Clean Architecture doesn’t enforce a particular paradigm, so you’re free to use an OOP or a functional style. In our case the client code can be quite simple:
client.py:
from typing import Any, Dict, List, Union
import requests
from .entities import Spell
# Use mypy recursive typing
JSON = Union[Dict[str, "JSON"], List["JSON"], str, int, float, bool, None]
BASE_URL = "https://wizard-world-api.herokuapp.com"
def fetch_spells_payload() -> JSON:
req = requests.get(f"{BASE_URL}/Spells")
# Avoid error handling boiler plate and crash if we don't get 200 back
req.raise_for_status()
return req.json()
def process_spells(payload: JSON) -> list[Spell]:
return [Spell.from_dict(data) for data in payload]
def fetch_spells() -> list[Spell]:
return process_spells(fetch_spells_payload())
if __name__ == "__main__":
fetch_spells()
I voluntarily chose to create 3 functions:
fetch_spells_payload: queries the API and return the jsonprocess_spells: processes some json and returnSpellentitiesfetch_spells: users of the client should just call this function to get the spells
You might wonder why we didn’t simply do:
def fetch_spells2() -> list[Spells]:
req = requests.get(f"{BASE_URL}/Spells")
# Avoid error handling boiler plate and crash if we don't get 200 back
req.raise_for_status()
return [Spell.from_dict(data) for data in req.json()]
This is because fetch_spells2 is really hard to unit test properly. This
function performs some I/O (it queries the spells API) and then processes
the response. If you wanted to unit test it properly you would have no
choice but to mock the I/O
part. With the first approach, the processing of the json is completely
decoupled from the I/O which makes the function easy to unit test:
def test_process_spells():
data = [
{
"id": "fbd3cb46-c174-4843-a07e-fd83545dce58",
"name": "Opening Charm",
"incantation": "Aberto",
"effect": "Opens doors",
"canBeVerbal": True,
"type": "Charm",
"light": "Blue",
"creator": None,
}
]
target = [
Spell(
id="fbd3cb46-c174-4843-a07e-fd83545dce58",
name="Opening Charm",
incantation="Aberto",
effect="Opens doors",
canBeVerbal=True,
type="Charm",
light="Blue",
creator=None,
)
]
assert process_spells(data) == target
And frankly, I wouldn’t write more unit tests than that for the client:
- to test
fetch_spells_payload, you’ll have to mock the I/O. And you’ll end up simply testing the I/O, which gives you no value fetch_spellsis trivial, and uses a function that we already tested. Once again, you can mock the I/O, but that will not add any value
Storing data with a data registry
The data registry is also part of the Gateways layer. It will interact with the database, and it will allow us to store and query the spells. Because using a real database isn’t the purpose of this article, we’ll use tinydb. This library uses local json files to simulate a NoSQL document database.
from typing import Iterable
from tinydb import TinyDB
from .entities import Spell
class DataRegistry:
def __init__(self, db_path: str) -> None:
self.db = TinyDB(db_path)
def register_spell(self, spell: Spell) -> None:
table = self.db.table("spells")
table.insert(spell.to_dict())
def register_spells(self, spells: Iterable[Spell]) -> None:
table = self.db.table("spells")
table.insert_multiple([spell.to_dict() for spell in spells])
def fetch_spells(self) -> list[Spell]:
table = self.db.table("spells")
return [Spell.from_dict(doc) for doc in table.all()]
The DataRegistry class simply exposes three interfaces to interact with the
database:
register_spell: writes one spell to the DBregister_spells: writes several spells to the DBfetch_spells: reads all the spells from the DB
Note that the DataRegistry is the only class that will ever need to know
about the database’s specifics. If one day we decide to move away from tinydb
for something like Postgres, the rest of your codebase wouldn’t change.
Gluing everything together: CollectSpellsUseCase
We’re almost there! The UseCase is the last element of the Clean Architecture
that we need to see. The CollectSpellsUseCase will use the client to query
the spells from the API, and will then use the data registry to store the
spells. Once again, note that we’re free to use a class or simple functions
to implement a use case. Here I decided to implement it with a class:
from .data_registry import DataRegistry
from .entities import Spell
from .client import fetch_spells
class CollectSpellsUseCase:
def __init__(self, data_registry: DataRegistry) -> None:
self.reg = data_registry
def run(self) -> None:
spells = fetch_spells()
self.reg.register_spells(spells)
if __name__ == "__main__":
reg = DataRegistry("spells.json")
use_case = CollectSpellsUseCase(reg)
use_case.run()
If you run this snippet, you should see a spells.json file in your working
directory:
{
"spells": {
"1": {
"id": "fbd3cb46-c174-4843-a07e-fd83545dce58",
"name": "Opening Charm",
"incantation": "Aberto",
"effect": "Opens doors",
"canBeVerbal": true,
"type": "Charm",
"light": "Blue",
"creator": null
},
"2": {
"id": "5eb39a99-72cd-4d40-b4aa-b0f5dd195100",
"name": "Water-Making Spell",
"incantation": "Aguamenti",
"effect": "Conjures water",
"canBeVerbal": true,
"type": "Conjuration",
"light": "IcyBlue",
"creator": null
},
...
Conclusion
In this article, I tried to simply explain the concepts of the Clean Architecture. We also saw a practical implementation of these concepts in Python. Even though the example above is simple, it demonstrates how to implement common operations (fetching data from an API, storing data in a database) while benefiting from the decoupling provided by the Clean Architecture.